Key Concepts of Generative AI, LLMs, Textual and Foundation Models
Willkommen in unserem Blog, Ihrem Tor zur faszinierenden Welt der Generativen KI. In diesem Blog tauchen wir in die Kernkonzepte der generativen KI ein. Sie werden die Unterschiede zwischen generativer und diskriminativer KI, LLMs und Foundation Models kennenlernen. Sie erforschen die grundlegenden Architekturen von LLMs. Am Ende dieser Reise werden Sie mit einigen der bekanntesten Modelle in dieser transformativen Technologielandschaft gut vertraut sein. Machen Sie sich bereit für eine aufschlussreiche Reise in diese transformative Technologie.
-
Hauptkonzepte der Generativen KI
-
Schlüsselkonzepte von Textmodellen, LLMs und
Foundation Models
- Verweise
Hauptkonzepte der Generativen KI
In diesem Kapitel werden die wichtigsten Konzepte der generativen KI im Vergleich zu traditionellen KI-Modellen vorgestellt. Im Kern ist ein KI-Modell ein Framework, das auf Daten trainiert wird, um Vorhersagen oder Entscheidungen ohne explizite aufgabenspezifische Programmierung zu treffen.
Was ist ein generatives KI-Modell?
Ein generatives KI-Modell ist ein Modell der künstlichen Intelligenz, das darauf ausgelegt ist, neue Inhalte wie Text, Bilder oder Musik zu generieren, die den von Menschen erzeugten Inhalten sehr ähnlich sind. Diese Modelle werden auf umfangreichen Datensätzen mit bereits von Menschen erstellten Inhalten trainiert, um Muster, Stile und Strukturen in den Daten zu lernen.
Generative KI-Modelle verwenden in der Regel komplexe Algorithmen, die häufig auf neuronalen Netzen basieren, um die den Daten zugrunde liegenden Muster zu analysieren und zu verstehen. Einmal trainiert, können diese Modelle durch Extrapolation des Gelernten selbstständig neue Inhalte generieren.
Unterschiede zwischen diskriminativen und generativen KI-Modellen
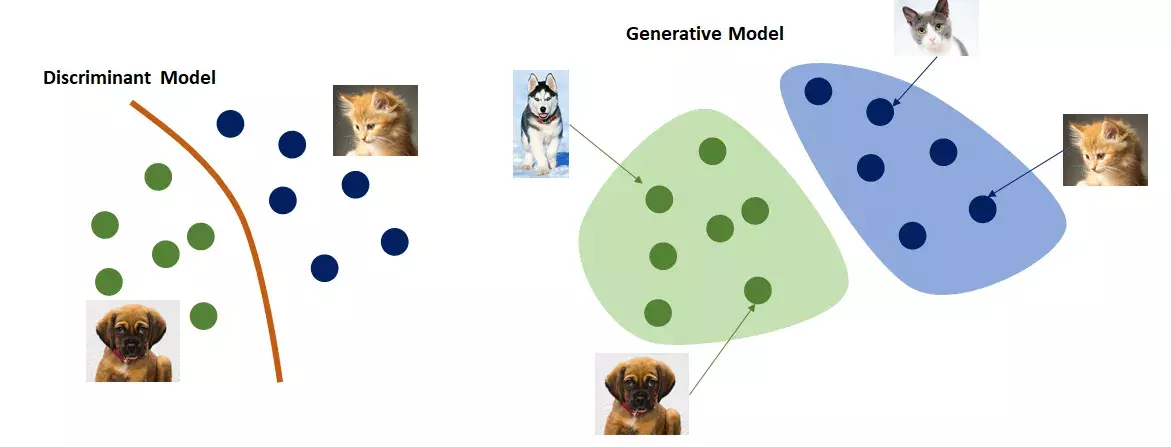
Generative und diskriminative Modelle[1]
Generative KI-Modelle unterscheiden sich deutlich von den klassischen diskriminativen KI-Modellen, die weiter verbreitet sind und bis jetzt der Standard beim maschinellen Lernen gewesen sind:
- Generative KI-Modelle erzeugen neue Daten, die der Verteilung der Trainingsdaten ähneln, während sich diskriminative KI-Modelle auf die Unterscheidung zwischen verschiedenen Kategorien innerhalb der Daten konzentrieren.
- Generative Modelle lernen unüberwacht aus Daten (ohne Lehrer/Labeling). Diskriminative Modelle benötigen in der Regel gelabelte Daten, um die Grenzen zwischen verschiedenen Klassen zu lernen.
- Diskriminative Modelle können manchmal in Kombination mit generativen Modellen verwendet werden. Ein diskriminatives Modell kann zum Beispiel verwendet werden, um zu bewerten, ob ein generierter Inhalt echt oder gefälscht ist, wie im Fall von GANs, bei denen ein Diskriminator beim Training des Generators hilft.
- Generative Modelle können synthetische Daten zur Datenerweiterung generieren, um die Robustheit von diskriminativen Modellen zu verbessern.[2]
Schlüsselkonzepte von Textmodellen, LLMs und Foundation Models
Im Folgenden werden wir uns mehr auf Textmodelle konzentrieren, da sie für uns besonders interessant sind. Textmodelle sind eine Art von KI-Modellen, die für die Generierung textbasierter Inhalte entwickelt wurden. Diese Modelle sind darauf trainiert, menschenähnlichen Text zu verstehen und zu erzeugen, was sie für Aufgaben wie die Generierung natürlicher Sprache, maschinelle Übersetzung, Textzusammenfassung und Chatbot-Antworten wertvoll macht. Sie können kohärente und kontextuell relevante Texte erstellen, indem sie Muster und Strukturen nutzen, die sie während des Trainings aus großen Textdatensätzen gelernt haben.
Architekturen von Textmodellen
Generative KI-Textmodelle umfassen verschiedene Architekturen, die darauf ausgelegt sind, Text zu produzieren oder zu verstehen. Hier geben wir einen Überblick über die wichtigsten Architekturansätze:
-
Rekurrente Neuronale Netze (RNNs): RNNs verarbeiten sequentielle Daten, wie z. B. Sätze in natürlicher Sprache oder Zeitreihendaten. Sie können für generative Aufgaben verwendet werden, indem sie das nächste Element in der Sequenz anhand der vorherigen Elemente vorhersagen. Allerdings sind RNNs bei der Erzeugung langer Sequenzen aufgrund des Problems des verschwindenden Gradienten eingeschränkt.[3]
-
Generative Adversarial Networks (GANs): GANs bestehen aus zwei neuronalen Netzen, dem Generator und dem Diskriminator, die in einem spielähnlichen Aufbau gegeneinander antreten. Der Generator erzeugt synthetische Daten, während die Aufgabe des Diskriminators darin besteht, zwischen echten und gefälschten Daten zu unterscheiden. Der Generator zielt darauf ab, immer realistischere Daten zu erzeugen, um den Diskriminator zu täuschen, während der Diskriminator seine Fähigkeit verbessert, echte von erzeugten Daten zu unterscheiden.[3]
-
Variationale Autoencoders (VAEs): VAEs sind generative Modelle, die lernen, Daten zu kodieren und sie dann wieder zu dekodieren, um die ursprünglichen Daten zu rekonstruieren. Sie bestehen aus einem neuronalen Netz mit Encoder und Decoder. Der Encoder wandelt die Eingaben in eine kompakte Repräsentation um, wobei relevante Informationen für den Decoder erhalten bleiben, um die ursprünglichen Daten zu rekonstruieren. Dies ermöglicht ein einfaches Sampling neuer Repräsentationen, um neue Daten zu erzeugen. Sie werden häufig für Text-, Audio- und Bilderzeugungsaufgaben eingesetzt.[4]
-
Autoregressive Modelle: Autoregressive Modelle erzeugen schrittweise Datenfolgen, wie z. B. Text- oder Zeitreihendaten. Diese Modelle stützen sich auf die vorherigen Elemente, die sie erzeugt haben, um das nächste Element in der Sequenz vorherzusagen und zu erzeugen. Sie werden häufig für Aufgaben wie die Texterstellung verwendet, bei der das Modell Wörter oder Zeichen auf der Grundlage der vorangegangenen generiert. Solche Modelle sind von grundlegender Bedeutung für die Erstellung kohärenter und kontextbewusster Datenfolgen.[5]
-
Transformatorbasierte Modelle: Transformatorbasierte Modelle sind ein Durchbruch in der generativen KI, der die Verarbeitung natürlicher Sprache und verschiedene Sequenz-zu-Sequenz-Aufgaben revolutioniert hat. Im Kern nutzen diese Modelle einen Mechanismus namens "Self-Attention", um kontextuelle Beziehungen zwischen Elementen in einer Sequenz zu erfassen, was sie beim Verstehen und Generieren von Text äußerst effizient macht.
Es ermöglicht die Abwägung der Bedeutung verschiedener Wörter oder Token in einem Satz, wenn jedes Wort unter Berücksichtigung seiner kontextuellen Relevanz verarbeitet wird. Dieser dynamische Aufmerksamkeitsmechanismus hilft dem Modell, weitreichende Abhängigkeiten und Beziehungen innerhalb der Eingabedaten zu verstehen.
Transformatoren bestehen aus einem Encoder und einem Decoder, die häufig bei Aufgaben wie der Sprachübersetzung eingesetzt werden. Der Encoder verarbeitet die Eingabesequenz mithilfe von Selbstbeobachtungsschichten, um kontextualisierte Darstellungen der einzelnen Wörter zu erstellen. Diese Repräsentationen werden dann vom Decoder verwendet, um die Ausgabesequenz Schritt für Schritt zu generieren.
Die Stanford-Forscher haben Transformatoren in einem Papier vom August 2021 als "Foundation-Modells" bezeichnet, weil sie in ihnen einen Paradigmenwechsel in der KI sehen.
Zu den bekanntesten transformatorbasierten Modellen gehören: GPT (Generative Pre-trained Transformer), BERT, RoBERTa, T5, XLNet, ELECTRA und andere.[6]
-
Flow-basierte Modelle: Diese Modelle beruhen auf einer Reihe reversibler Transformationen, um Daten von einer einfachen Verteilung auf eine komplexere abzubilden. Sie sind bekannt für ihre Fähigkeit, qualitativ hochwertige Samples zu generieren, und finden Anwendung in der Datenkompression, Bilderzeugung und Dichteschätzung. Flow-basierte Modelle werden für ihre Fähigkeit geschätzt, realistische und vielfältige Daten in hochdimensionalen Räumen zu erzeugen.[7]
-
Diffusionsmodelle: Diffusionsmodelle erzeugen Daten, indem sie iterativ Rauschen auf eine anfängliche Eingabe anwenden. Sie werden verwendet, um den Prozess zu modellieren, wie sich Daten im Laufe der Zeit entwickeln oder diffundieren. Diese Modelle beginnen mit einem beobachteten Datenpunkt und verfeinern diesen iterativ, indem sie bei jedem Schritt kontrolliertes Rauschen hinzufügen und schließlich einen neuen Datenpunkt erzeugen. Sie sind besonders leistungsstark, da sie einen probabilistischen Rahmen für das Verständnis und die Erzeugung komplexer Daten bieten.[8]
Large Language Models (LLMs)
Large Language Models (LLMs) stellen einen bemerkenswerten Fortschritt im Bereich der Textmodelle dar, die speziell für das Verstehen und Erzeugen menschlicher Sprache entwickelt wurden. Während alle LLMs unter die umfassendere Kategorie der Textmodelle fallen, unterscheiden sie sich durch ihren schieren Umfang und ihren Fokus auf die Verarbeitung natürlicher Sprache, wobei sie vorwiegend die Transformer-Architektur nutzen.
Diese Architektur mit ihrem bahnbrechenden Mechanismus der Selbstaufmerksamkeit war entscheidend für die Revolutionierung natürlichsprachlicher Aufgaben, da sie es LLMs ermöglicht, die Nuancen und den Kontext jedes Worts in einem Satz zu verstehen[9]. Dank ihrer Fähigkeit, auf umfangreichen Textdatenquellen, einschließlich Büchern, Wikipedia und anderen Online-Inhalten, trainiert zu werden, können LLMs menschenähnliche Antworten geben und komplizierte Aufgaben lösen, was sie zur Grundlage zahlreicher Anwendungen in der natürlichen Sprachverarbeitung und der maschinellen Übersetzung macht.
Im Zusammenhang mit LLM verweisen Experten häufig auf die ihnen zugrunde liegende Basis: Foundation-Modells.
-
Foundation-Modell ist ein großes Modell für ML, das auf einer großen Menge von Textdaten so trainiert wurde, dass es für nachgelagerte Aufgaben verwendet werden kann. Es dient als Basis oder Ausgangspunkt für die Entwicklung speziellerer LLMs.[10]
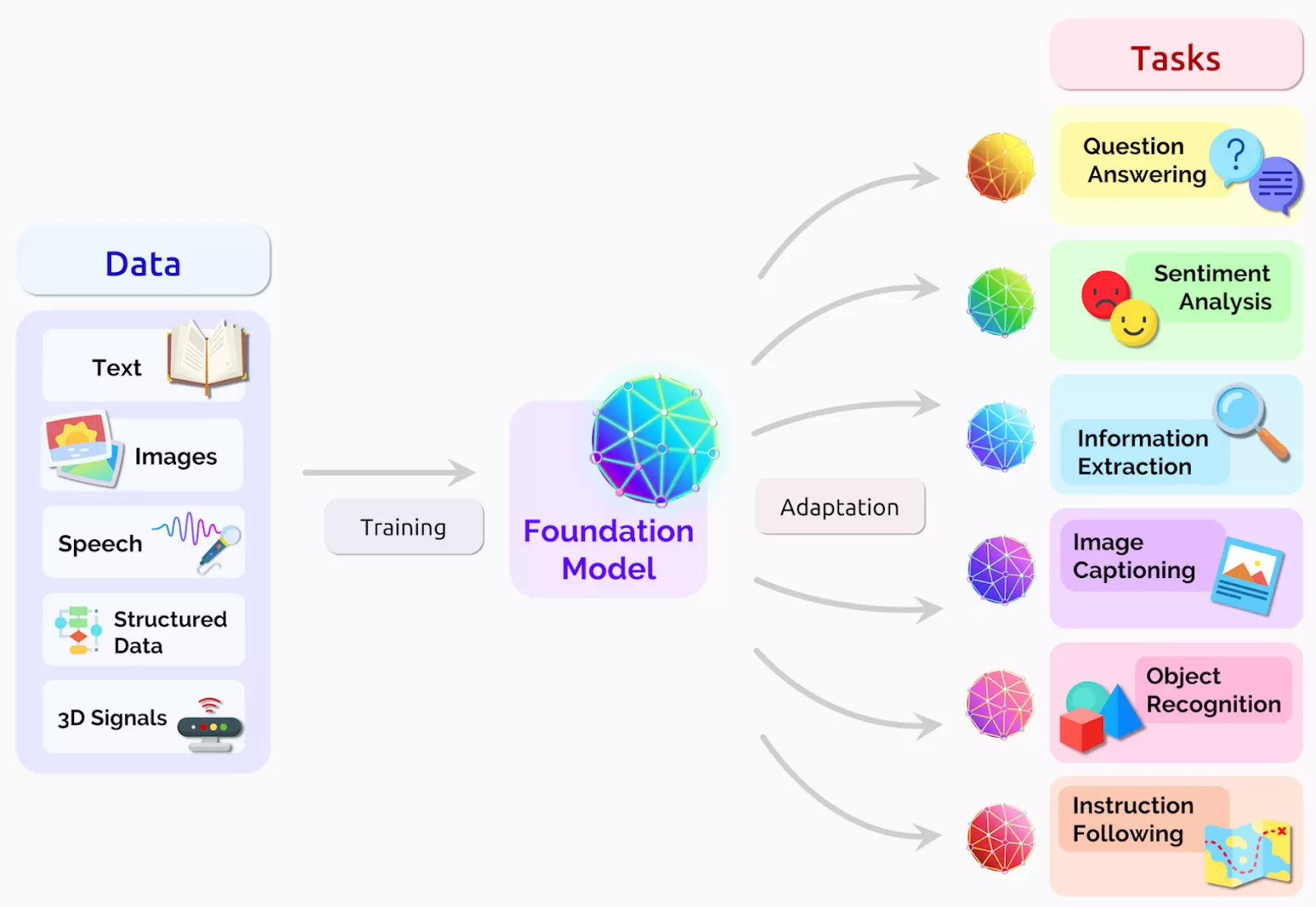
Foundation-Modell[11]
-
LLMs sind spezifische Instanzen oder Variationen des Foundation-Modells, die Deep Learning bei Aufgaben der natürlichen Sprachverarbeitung (NLP) und der natürlichen Sprachgenerierung (NLG) einsetzen. Sie werden durch Feinabstimmung des vorab trainierten Foundation-Modells auf bestimmte Aufgaben oder Datensätze erstellt. Der Feinabstimmungsprozess ermöglicht die Anpassung des Modells an bestimmte Bereiche, Branchen oder Anwendungsfälle. Durch die Feinabstimmung wird das Modell immer spezieller und für die jeweilige Aufgabe optimiert, für die es entwickelt wurde.[12]
Populäre LLMs
Im Folgenden geben wir einen Überblick über die populärsten und am häufigsten verwendeten LLMs:
-
GPT-4 (OpenAI)
Das Modell GPT-4, das im März 2023 von OpenAI veröffentlicht wurde, ist die beste KI-LLM des Jahres. Es verfügt über außergewöhnliche Fähigkeiten in den Bereichen komplexes logisches Denken, fortgeschrittene Codierung, Beherrschung mehrerer akademischer Fächer, Leistung auf menschlichem Niveau und mehr. Darüber hinaus ist es das erste multimodale Modell, das sowohl Text- als auch Bildeingaben verarbeiten kann, obwohl diese Funktion noch nicht in ChatGPT integriert ist.
GPT-4 hat außerdem erhebliche Fortschritte bei der Behandlung von Halluzinationen und der Verbesserung der Faktizität gemacht und erreicht im Vergleich zu GPT-3.5 eine beeindruckende Faktengenauigkeit von 80% in verschiedenen Kategorien. OpenAI hat beträchtliche Anstrengungen unternommen, um GPT-4 durch Reinforcement Learning from Human Feedback (RLHF) und rigorose Tests mit Domänenexperten an menschliche Werte anzupassen.
1,8 Billionen Parameter und die Unterstützung einer maximalen Kontextlänge von 32.768 Token machen das OpenAI GPT-4 Modell zweifelsohne zur besten LLM-Wahl für 2023.
-
GPT-3.5 (OpenAI)
Hierbei handelt es sich um ein vielseitiges LLM, das GPT-4 ähnelt, dem es aber an bereichsspezifischem Fachwissen mangelt. Als positiv anzumerken ist, dass es außergewöhnlich schnell ist und schnelle Antworten für Aufgaben wie das Schreiben von Aufsätzen und die Erstellung von Geschäftsplänen mit ChatGPT liefert. OpenAI hat zusätzlich eine größere Kontextlänge von 16K für das GPT-3.5 Turbo-Modell eingeführt, das kostenlos und ohne zeitliche Beschränkung genutzt werden kann.
GPT-3.5 ist jedoch anfällig für Halluzinationen und produziert häufig falsche Informationen. Trotz dieses Nachteils erbringt es gute Leistungen bei grundlegenden Codierungsfragen, Übersetzungen, dem Verstehen wissenschaftlicher Konzepte und kreativen Aufgaben.
Beim HumanEval-Benchmark erzielte GPT-3.5 48,1 %, während GPT-4 mit 67 % die höchste Punktzahl unter den allgemeinen großen Sprachmodellen erreichte. GPT-3.5 wurde mit 175 Milliarden Parametern trainiert.
-
PaLM 2 (Google)
Das PaLM 2-Modell von Google priorisiert den gesunden Menschenverstand, formale Logik, Mathematik und fortgeschrittene Kodierung in über 20 Sprachen. Das größte Modell verfügt über 540 Milliarden Parameter und hat eine maximale Kontextlänge von 4096 Token.
Google hat 4 PaLM 2-basierte Modelle eingeführt: Gecko, Otter, Bison und Unicorn. Bison ist derzeit verfügbar und erreichte im MT-Bench-Test eine Punktzahl von 6,40, während GPT-4 8,99 Punkte erreichte.
In Reasoning-Tests wie WinoGrande, StrategyQA, XCOPA und anderen zeichnet sich PaLM 2 aus und übertrifft GPT-4. Es ist auch ein mehrsprachiges Modell mit der Fähigkeit, Idiome, Rätsel und nuancierte Texte aus verschiedenen Sprachen zu verstehen, eine Herausforderung für andere LLMs. Darüber hinaus bietet der PaLM 2 schnelle Antworten und liefert drei Antworten gleichzeitig.
-
LLaMA 2 (Meta)
LLaMA 2 ist eine Familie von großen Sprachmodellen von Meta AI mit 7B bis 70B Parametern, die sich auf Dialoganwendungen konzentrieren. Es übertrifft bei verschiedenen Benchmarks durchweg Open-Source-Chat-Modelle, was es zu einem potenziellen Ersatz für Closed-Source-Modelle macht, wie die menschlichen Bewertungen von Meta in Bezug auf Hilfsbereitschaft und Sicherheit zeigen.
LLaMA 2 basiert auf der Google-Transformer-Architektur mit Erweiterungen und enthält Funktionen wie RMSNorm-Vornormalisierung (inspiriert von GPT-3), SwiGLU-Aktivierungsfunktion (inspiriert von Googles PaLM), Multi-Query-Attention und Rotary Positional Embeddings (RoPE, inspiriert von GPT Neo). LLaMA 2 unterscheidet sich von seinem Vorgänger vor allem durch die größere Kontextlänge (4096 vs. 2048 Token) und die Verwendung von Aufmerksamkeit für gruppierte Abfragen in den größeren Modellen.
Die Trainingsdaten umfassen eine Mischung aus öffentlich zugänglichen Quellen, mit Ausnahme von Metas eigenen Daten.
-
Falcon
Falcon ist ein Open-Source Large Language Model (LLM), das vom Technology Innovation Institute (TII) in den Vereinigten Arabischen Emiraten entwickelt wurde. Es wird unter der freizügigen Apache-2.0-Lizenz veröffentlicht, die eine kommerzielle Nutzung ohne Lizenzgebühren oder Einschränkungen ermöglicht.
Das TII bietet zwei Falcon-Modelle mit 40B- und 7B-Parametern an. Für Chat-Anwendungen empfiehlt sich das Modell Falcon-40B-Instruct, das auf verschiedene Anwendungsfälle abgestimmt ist. Falcon ist in erster Linie auf Englisch, Deutsch, Spanisch und Französisch trainiert, unterstützt aber auch Italienisch, Portugiesisch, Polnisch, Niederländisch, Rumänisch, Tschechisch und Schwedisch.
-
Cohere
Cohere wurde von ehemaligen Mitgliedern des Google Brain-Teams gegründet und hat sich auf generative KI-Lösungen für Unternehmen spezialisiert. Das Unternehmen bietet eine Vielzahl von Modellen mit 6B bis 52B Parametern an. Vor allem das Cohere Command-Modell wurde für seine Genauigkeit gelobt und erreichte laut Stanford HELM die höchste Genauigkeit unter Gleichaltrigen. Führende Unternehmen wie Spotify, Jasper und HyperWrite vertrauen auf die Modelle von Cohere, um ihre KI-gesteuerten Erfahrungen zu verbessern.
-
Claude 2 und Claude 1
Claude, entwickelt von Anthropic und unterstützt von Google, konzentriert sich auf die Entwicklung hilfreicher, ehrlicher und sicherer KI-Assistenten. In Benchmarks haben sich die Modelle Claude v1 und Claude Instant als vielversprechend erwiesen, wobei Claude v1 in MMLU- und MT-Bench-Tests besser abschnitt als PaLM 2. Claude v1 ist dem GPT-4 dicht auf den Fersen und erreicht im MT-Bench-Test 7,94 Punkte im Vergleich zu 8,99 Punkten von GPT-4. Im MMLU-Benchmark erreicht Claude v1 75,6 Punkte, während GPT-4 86,4 Punkte erzielt. Anthropic war auch das erste Unternehmen, das 100k Token als größtes Kontextfenster in seinem Claude-instant-100k-Modell anbot.
Claude 2 zeigt beeindruckende Verbesserungen, die über die API und die neue Website claude.ai zugänglich sind. Bei den GRE-Prüfungen zum Lesen und Schreiben übertrifft er das 90. Perzentil und schneidet beim quantitativen Denken ähnlich gut ab wie der Durchschnittsbewerber.[13]
Hier ist ein umfassender Überblick über die am häufigsten verwendeten LLMs:
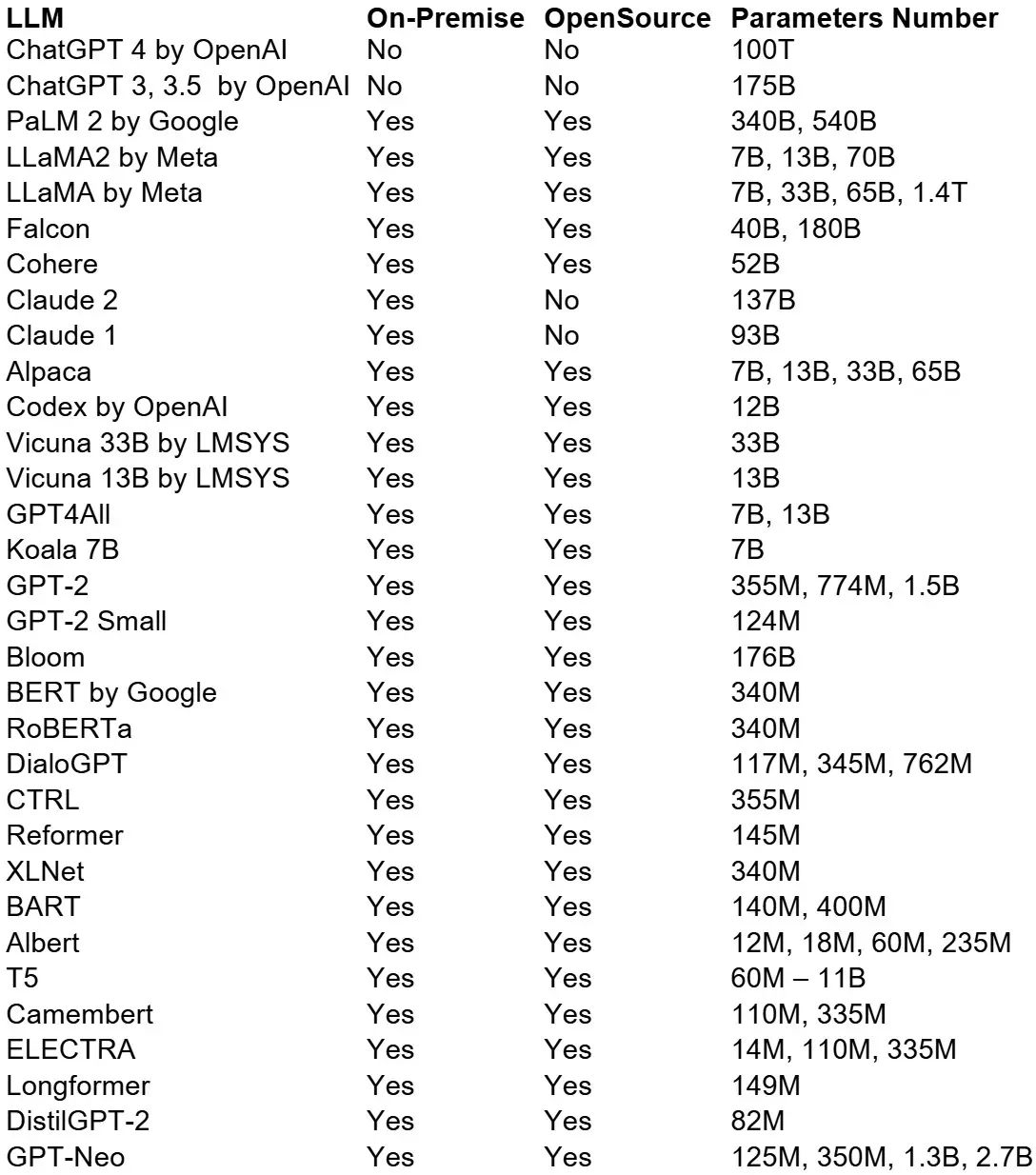
Beispiele für populäre LLMs
"Enterprise AI in Action" Whitepaper
Danke! Hier ist Ihr Download-Link:
Verweise
- [1] About Generative and Discriminative models
-
[2] Background:
What is a Generative Model? | Machine Learning | Google for Developers
Generative vs. Discriminative Machine Learning Models - [3] Unveiling 6 Types of Generative AI
- [4] Variational Autoencoders
- [5] Unveiling 6 Types of Generative AI
-
[6] Unveiling
6 Types of Generative AI
What Is a Transformer Model? | NVIDIA
Most Powerful Machine Learning Models Explained (Transformers, CNNs, RNNs, GANs …) - [7] Flow-based generative model | Wikipedia
-
[8] Types of Generative AI
Models Explained [Diffusion GAN VAEs]
What is Generative AI? | NVIDIA -
[9] Are
Generative AI And Large Language Models The Same Thing?
What are LLMs, and how are they used in generative AI?
Generative artificial intelligence | Wikipedia Introduction to LLMs and the generative AI : Part 1 — LLM Architecture, Prompt Engineering and LLM Configuration - [10] Large Language Models: Complete Guide in 2023
- [11] On the Opportunities and Risks of Foundation Models
-
[12] Large Language
Models: Complete Guide in 2023
Large language model | Wikipedia -
[13] 12 Best Large
Language Models (LLMs) in 2023
Meta and Microsoft Introduce the Next Generation of Llama
Claude 2



