Key Concepts of Generative AI, LLMs, Textual and Foundation Models
Welcome to our blog, your gateway to the fascinating world of Generative AI. In this blog, we'll dive into the core concepts of Generative AI. You'll uncover the distinctions between generative and discriminative AI, LLMs, and Foundation Models. Explore the fundamental architectures of LLMs. By the end of this journey, you'll be well-acquainted with some of the most widely recognized models in this transformative technology landscape. Get ready for an insightful journey into this transformative technology.
Key Concepts of Generative AI
In this chapter, we explore the primary concepts of generative AI in comparison to traditional AI models. At its core, an AI model is a computational framework trained on data to make predictions or decisions without explicit task-specific programming.
What is a generative AI model?
A generative AI model is a type of artificial intelligence model designed to generate new content, such as text, images, or music, that closely resembles content created by humans. These models are trained on vast datasets of existing human-generated content to learn patterns, styles, and structures present in the data.
Generative AI models typically employ complex algorithms, often based on neural networks, to analyse and understand the underlying patterns within the data. Once trained, these models can generate new content autonomously by extrapolating from what they have learned.
Differences between discriminative AI and generative AI models
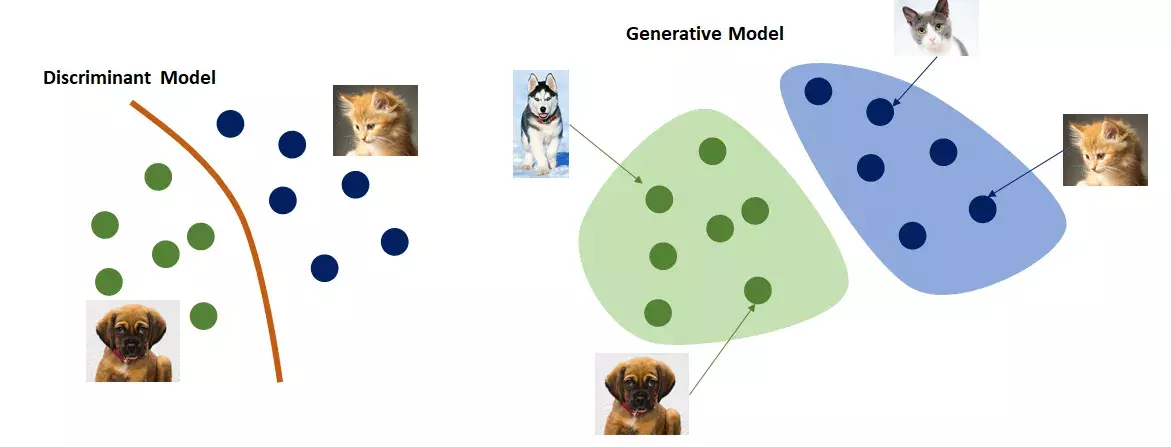
Generative and Discriminative Models[1]
Generative AI models differ notably from the classic discriminative AI models, which have been more prevalent and, until recently, were the standard in machine learning:
- Generative AI models create new data that resembles the training data distribution, while discriminative AI models focus on distinguishing between different categories within the data.
- Generative models learn from data in an unsupervised manner (without teacher/labelling). Discriminative models usually require labelled data to learn the boundaries between different classes.
- Discriminative models can sometimes be used in combination with generative models. For example, a discriminative model might be used to evaluate whether a piece of generated content is real or fake, as in the case of GANs, where a discriminator helps train the generator.
- Generative models can generate synthetic data for data augmentation to improve robustness of discriminative models[2]
Key Concepts of Textual Models, LLMs and Foundation Models
In the following, we will focus more on textual models, as they are of particular interest to us. Textual model is a type of AI model designed to generate text-based content. These models are trained to understand and generate human-like text, making them valuable for tasks like natural language generation, machine translation, text summarization, and chatbot responses. They can create coherent and contextually relevant text by leveraging patterns and structures learned from large text datasets during training.
Architectures of textual models
Generative AI textual models encompass various architectures designed to produce or understand text. Here, we present on overview of the main architectural approaches:
-
Recurrent Neural Networks (RNNs): RNNs process sequential data, such as natural language sentences or time-series data. They can be used for generative tasks by predicting the next element in the sequence given the previous elements. However, RNNs are limited in generating long sequences due to the vanishing gradient problem.[3]
-
Generative adversarial networks (GANs): GANs consist of two neural networks, the generator and the discriminator, that compete against each other in a game-like setup. The generator generates synthetic data, while the discriminator’s task is to distinguish between real and fake data. The generator aims to create increasingly realistic data to deceive the discriminator, while the discriminator improves its ability to differentiate real from generated data.[3]
-
Variational autoencoders (VAEs): VAEs are generative models that learn to encode data and then decode it back to reconstruct the original data. They consist of an encoder and decoder neural network. The encoder converts input into a compact representation, preserving relevant information for the decoder to reconstruct the original data. This enables easy sampling of new representations to generate novel data. They are commonly used in text, audio and image generation tasks.[4]
-
Autoregressive Models: Autoregressive models generate sequences of data, such as text or time series data, one step at a time. These models rely on the previous elements they have generated to predict and generate the next element in the sequence. They are often used for tasks like text generation, where the model generates words or characters based on the preceding ones. Such models are fundamental for creating coherent and context-aware sequences of data.[5]
-
Transformer-based Models:Transformer-based models are a breakthrough in generative AI that revolutionised natural language processing and various sequence-to-sequence tasks. At their core, these models employ a mechanism called "self-attention" to capture contextual relationships between elements in a sequence, making them highly effective in understanding and generating text.
It allows weighing the importance of different words or tokens in a sentence when processing each word, considering their contextual relevance. This dynamic attention mechanism helps the model understand long-range dependencies and relationships within the input data. In essence, it enables the model to focus more on the words that matter most for each prediction.
Transformers consist of an encoder and a decoder, often used in tasks like language translation. The encoder processes the input sequence using self-attention layers to create contextualised representations of each word. These representations are then used by the decoder to generate the output sequence step by step.
Stanford's researchers have called transformers “foundation models” in an August 2021 paper because they see them driving a paradigm shift in AI.
Most famous transformer-based models include: GPT (Generative Pre-trained Transformer), BERT, RoBERTa, T5, XLNet, ELECTRA and others.[6]
-
Flow-Based Models: These models rely on a series of reversible transformations to map data from a simple distribution to a more complex one. They are known for their ability to generate high-quality samples and have applications in data compression, image generation and density estimation. Flow-based models are valued for their capacity to generate realistic and diverse data in high-dimensional spaces.[7]
-
Diffusion Models: Diffusion models generate data by iteratively applying noise to an initial input. They are used to model the process of how data evolves or diffuses over time. These models start with an observed data point and iteratively refine it by adding controlled noise at each step, ultimately generating a new data point.
They are particularly powerful because they provide a probabilistic framework for understanding and generating complex data.
Diffusion models can take longer to train than VAEs, but they can handle hundreds of layers, offering high-quality output for generative AI models.[8]
Large Language Models (LLMs)
Large Language Models (LLMs) represent a remarkable advancement in the realm of textual models, specifically designed to comprehend and generate human language. While all LLMs fall under the broader category of textual models, they distinguish themselves by their sheer scale and focus on processing natural language, predominantly using the transformer architecture.
This architecture, with its pioneering self-attention mechanism, has been pivotal in revolutionising natural language tasks, allowing LLMs to understand the nuances and context of each word in a sentence.[9] As a result, with their capability to be trained on extensive text data sources, including books, Wikipedia, and other online content, LLMs can deliver humanesque responses and master intricate tasks, making them the bedrock for numerous applications in natural language processing and machine translation.
In the context of LLMs, experts often refer to their underlying basis: foundation models.
-
Foundation model is a large ML model that has been trained on a vast amount of text data in such a manner that it can be used for downstream tasks. It serves as a base or starting point for developing more specialised LLMs.[10]
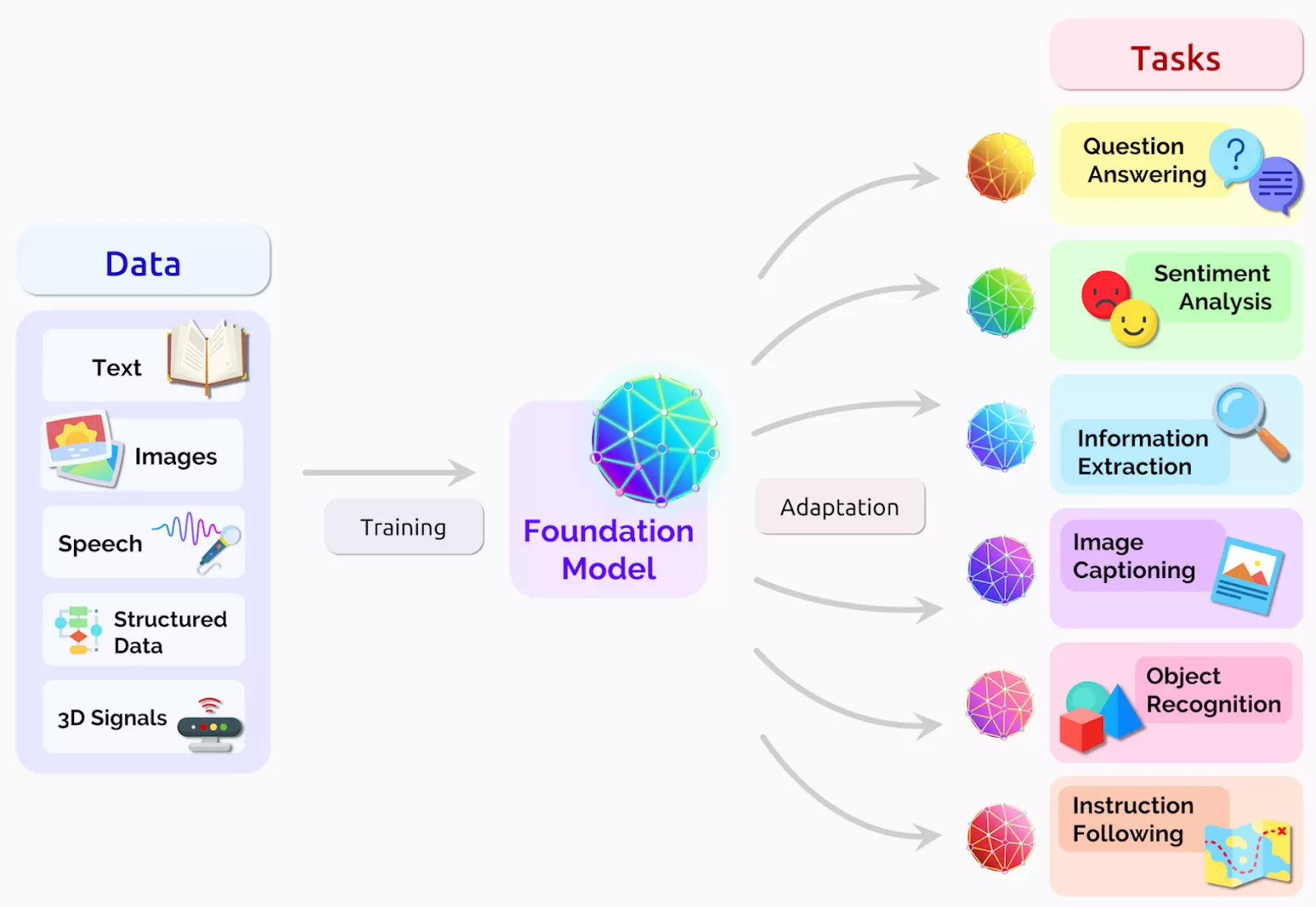
Foundation model[11]
-
LLMs are specific instances or variations of the Foundation Model that utilise deep learning in natural language processing (NLP) and natural language generation (NLG) tasks. They are created by fine-tuning the pre-trained Foundation Model on specific tasks or datasets. The fine-tuning process allows the model to adapt to particular domains, industries, or use cases. By fine-tuning, the model becomes more specialised and optimised for the specific task it's designed for.[12]
Popular LLMs
Here is an overview of the most popular and widely used LLMs:
-
GPT-4 (OpenAI)
The GPT-4 model, released in March 2023 by OpenAI, stands as the premier AI LLM of the year. It boasts exceptional capabilities in complex reasoning, advanced coding, mastery of multiple academic subjects, human-level performance, and more. Additionally, it's the pioneer multimodal model, accommodating both text and image inputs, although this feature is not yet integrated into ChatGPT.
Moreover, GPT-4 has made significant strides in addressing hallucination and enhancing factuality, achieving an impressive 80% factual accuracy across various categories when compared to GPT-3.5. OpenAI has invested considerable effort in aligning GPT-4 with human values through Reinforcement Learning from Human Feedback (RLHF) and rigorous adversarial testing with domain experts.
With 1.8 trillion parameters and support for a maximum context length of 32,768 tokens, the OpenAI GPT-4 model unquestionably reigns supreme as the best LLM choice for 2023.
-
GPT-3.5 (OpenAI)
It's a versatile LLM similar to GPT-4 but lacks domain-specific expertise. On the plus side, it's exceptionally fast, providing rapid responses for tasks like essay writing and business plan generation with ChatGPT. OpenAI has also introduced a larger 16K context length for the GPT-3.5 Turbo model, and it's free to use with no time restrictions.
However, GPT-3.5 is prone to hallucinations and frequently produces false information. Despite this drawback, it performs well for basic coding questions, translation, understanding science concepts, and creative tasks.
In terms of the HumanEval benchmark, GPT-3.5 scored 48.1%, whereas GPT-4 achieved the highest score of 67% among general-purpose large language models. GPT-3.5 is trained on 175 billion parameters.
-
PaLM 2 (Google)
Google's PaLM 2 model prioritises common-sense reasoning, formal logic, mathematics, and advanced coding across 20+ languages. The largest model boasts 540 billion parameters and a maximum context length of 4096 tokens.
Google introduced 4 PaLM 2-based models: Gecko, Otter, Bison, and Unicorn. Bison is currently available and achieved a 6.40 score in the MT-Bench test, while GPT-4 scored 8.99 points.
In reasoning assessments like WinoGrande, StrategyQA, XCOPA, and others, PaLM 2 excels, outperforming GPT-4. It's also a multilingual model with the ability to comprehend idioms, riddles, and nuanced texts from various languages, a challenge for other LLMs. Furthermore, PaLM 2 offers quick responses and provides three responses simultaneously.
-
LLaMA 2 (Meta)
LLaMA 2 is a family of large language models by Meta AI, ranging from 7B to 70B parameters, focusing on dialogue applications. It consistently outperforms open-source chat models on various benchmarks, making it a potential substitute for closed-source models, as per Meta's human evaluations for helpfulness and safety.
Built upon the Google transformer architecture with enhancements, LLaMA 2 incorporates features like RMSNorm pre-normalization (inspired by GPT-3), SwiGLU activation function (inspired by Google's PaLM), multi-query attention, and rotary positional embeddings (RoPE, inspired by GPT Neo). LLaMA 2's key distinctions from its predecessor are its increased context length (4096 vs. 2048 tokens) and the use of grouped-query attention in the larger models.
Its training data includes a mix of publicly available sources, excluding Meta's proprietary data.
-
Falcon
Falcon is an open-source Large Language Model (LLM) developed by the Technology Innovation Institute (TII) in the UAE. It's released under the permissive Apache 2.0 licence, allowing for commercial use without royalties or restrictions.
TII offers two Falcon models, with 40B and 7B parameters. For chat applications, the recommended choice is the Falcon-40B-Instruct model, fine-tuned for various use cases. While primarily trained in English, German, Spanish, and French, Falcon also supports Italian, Portuguese, Polish, Dutch, Romanian, Czech, and Swedish languages.
-
Cohere
Cohere, established by ex-Google Brain team members, is dedicated to enterprise-focused generative AI solutions. They offer a variety of models, ranging from 6B to 52B parameters. Notably, their Cohere Command model has received acclaim for its accuracy, ranking highest in accuracy among peers according to Stanford HELM. Leading companies like Spotify, Jasper, and HyperWrite rely on Cohere's models to enhance their AI-driven experiences.
-
Claude 2 and Claude 1
Claude, developed by Anthropic and backed by Google, focuses on creating helpful, honest, and safe AI assistants. In benchmarks, Claude v1 and Claude Instant models have shown promise, with Claude v1 outperforming PaLM 2 in MMLU and MT-Bench tests. Claude v1 closely rivals GPT-4, scoring 7.94 in the MT-Bench test compared to GPT-4's 8.99. In the MMLU benchmark, Claude v1 achieves 75.6 points, while GPT-4 scores 86.4. Anthropic also became the first company to offer 100k tokens as the largest context window in its Claude-instant-100k model.
Claude 2 shows impressive improvements, accessible through API and the new website, claude.ai. It excels on GRE reading and writing exams, surpassing the 90th percentile, and performs similarly to the median applicant on quantitative reasoning.[13]
Here is a comprehensive overview of the most commonly used LLMs:
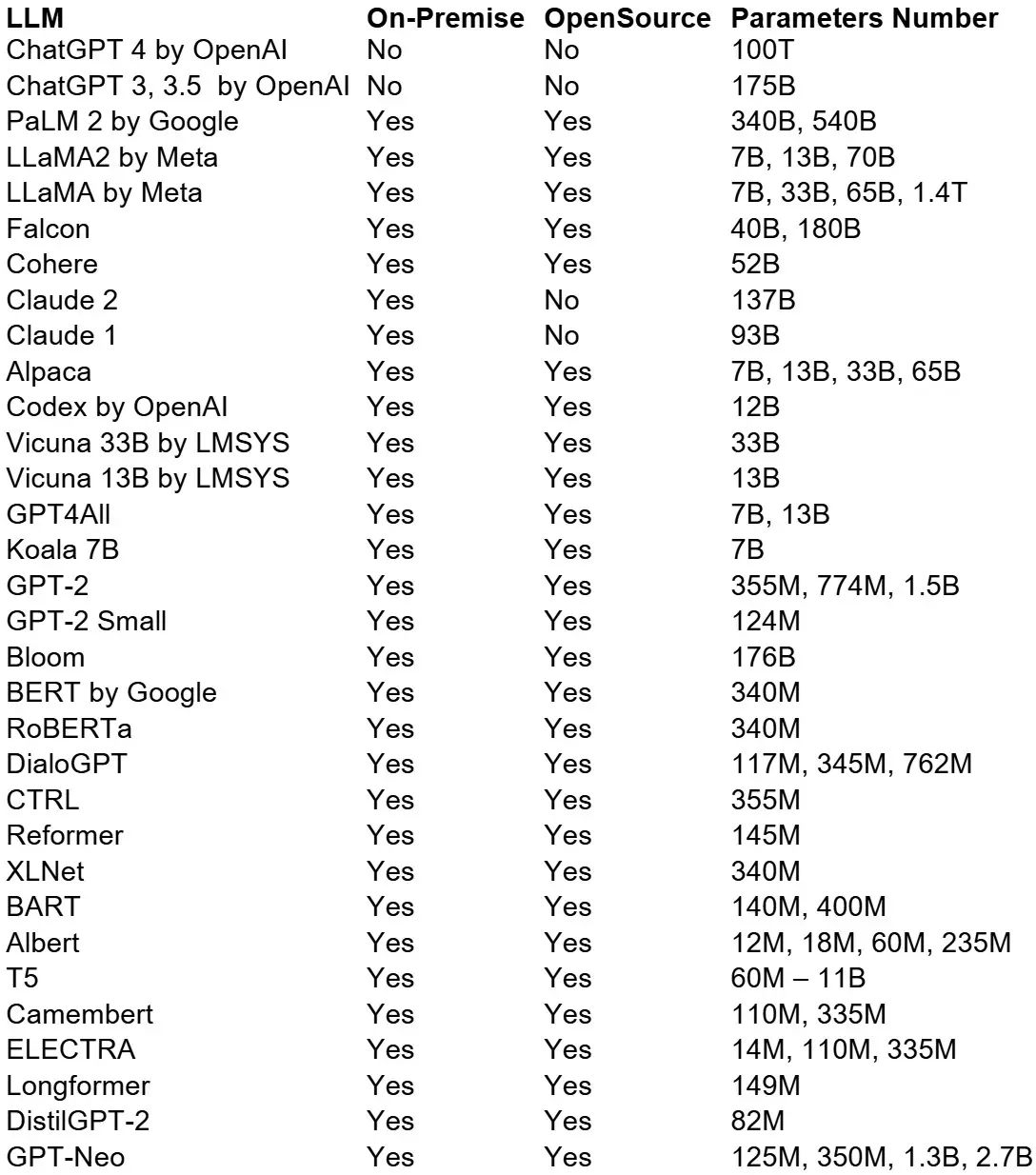
Examples of popular LLMs
"Enterprise AI in Action" Whitepaper
Thanks! Here is your download-link:
References
- [1] About Generative and Discriminative models
-
[2] Background:
What is a Generative Model? | Machine Learning | Google for Developers
Generative vs. Discriminative Machine Learning Models - [3] Unveiling 6 Types of Generative AI
- [4] Variational Autoencoders
- [5] Unveiling 6 Types of Generative AI
-
[6] Unveiling
6 Types of Generative AI
What Is a Transformer Model? | NVIDIA
Most Powerful Machine Learning Models Explained (Transformers, CNNs, RNNs, GANs …) - [7] Flow-based generative model | Wikipedia
-
[8] Types of Generative AI
Models Explained [Diffusion GAN VAEs]
What is Generative AI? | NVIDIA -
[9] Are
Generative AI And Large Language Models The Same Thing?
What are LLMs, and how are they used in generative AI?
Generative artificial intelligence | Wikipedia Introduction to LLMs and the generative AI : Part 1 — LLM Architecture, Prompt Engineering and LLM Configuration - [10] Large Language Models: Complete Guide in 2023
- [11] On the Opportunities and Risks of Foundation Models
-
[12] Large Language
Models: Complete Guide in 2023
Large language model | Wikipedia -
[13] 12 Best Large
Language Models (LLMs) in 2023
Meta and Microsoft Introduce the Next Generation of Llama
Claude 2



