Generative AI: Advanced Customization Techniques
Willkommen in unserem Blog. In diesem Post werden wir LLM-Anpassungstechniken vorstellen, die es ermöglichen, Ihre eigenen Daten als Wissensbasis zu verwenden. Sie werden lernen, was Prompt Engineering, Embeddings und eine Feinabstimmung sind. Weiterhin werden Sie ein praktisches Beispiel für die Erstellung eines digitalen Marketing-Assistenten mit dem LangChain-Framework sehen. Sie erhalten auch Informationen über alternative Ansätze zur Erstellung solcher Assistenten, ob in der Cloud oder On Premise.
- Einführung
-
Anpassungstechniken
-
Showcase: Entwicklung eines digitalen Marketing-Assistenten
mithilfe des LangChain-Frameworks
-
Weitere Ansätze zum Aufbau eines digitalen
Marketingassistenten
- Verweise
Einführung
Im Unternehmenskontext erfordert die Umsetzung verschiedener Anwendungsfälle detaillierte Anpassungsansätze. Die meisten Unternehmen verfügen über einzigartige Datensätze, die von Standard-KI-Modellen unberührt bleiben. Um robuste KI-Assistenten zu entwickeln, die auf solche unternehmensspezifischen Informationen zugeschnitten sind, reicht es daher nicht aus, sich nur auf vor-trainierte Modelle zu beschränken. Stattdessen kommen spezielle Techniken ins Spiel, die sicherstellen, dass die KI die Besonderheiten der Daten versteht und sinnvoll damit umgeht. Der folgende Abschnitt befasst sich mit einigen fortgeschrittenen Anpassungsmethoden, die dies möglich machen.
Anpassungstechniken
Bei der Beantwortung von domänenspezifischen Anfragen, die auf einzigartigen Unternehmensdaten basieren, reichen Standard-KI-Modelle unter Umständen nicht aus, da sie mit solchen speziellen Inhalten nicht vertraut sind. In solchen Situationen sind fortgeschrittene Anpassungstechniken der generativen KI erforderlich:
- Prompt-Engineering erleichtert die Konstruktion von Eingabeabfragen, die auf spezifische Daten und Anfragen zugeschnitten sind, und stellt sicher, dass das Modell die zugrunde liegende Absicht erkennt.
- Embeddings spielen eine wichtige Rolle bei der Kodierung der Semantik und helfen dem LLM dabei, den Kontext und die Feinheiten der domänenspezifischen Sprache zu erfassen.
- Die Feinabstimmung verfeinert das LLM, um es auf die Unternehmensdaten abzustimmen, seine Leistung zu optimieren und die Kongruenz mit der jeweiligen Branche oder dem jeweiligen Bereich sicherzustellen. Ohne diese Verfeinerung könnte das Modell nicht in der Lage sein, genaue oder sachdienliche Antworten in Bezug auf Unternehmensdaten zu liefern, da es an kontextbezogenem Bewusstsein und spezialisiertem Verständnis für die geschützten Informationen einer Organisation mangelt.
Alle diese Techniken machen LLMs zu hocheffizienten Werkzeugen für die Verarbeitung und Extraktion von Erkenntnissen aus Ihren eigenen Daten. Solche fortgeschrittenen Techniken sind besonders wichtig, wenn:
- Präzision ist wichtig: Wenn Sie präzise und kontrollierte Antworten von einem LLM benötigen, können Sie mithilfe von Prompt-Engineering dessen Ausgabe effektiv steuern.
- Semantisches Verständnis ist wichtig: Wenn Ihre Anwendung ein tiefes Verständnis von Wortbedeutungen und Kontext erfordert, können Embeddings helfen, indem sie Sprache in einer mathematischen, vektorisierten Form darstellen.
- Spezialisierte Aufgaben: Für Aufgaben, die bereichs- oder kontextspezifisches Fachwissen erfordern, können Sie den LLM so anpassen, dass Sie sich in diesen Bereichen auszeichnen.
- Verbesserte Leistung: Wenn Sie die Leistung des LLM bei einer bestimmten Aufgabe oder in einem bestimmten Bereich deutlich verbessern wollen, können diese Techniken genauere und kontextbezogene Ergebnisse liefern.
- Optimierung der Ressourcen: Je nach den Ihnen zur Verfügung stehenden Ressourcen können diese Techniken einzeln oder in Kombination eingesetzt werden, um die Fähigkeiten des Modells effizient zu optimieren.
Weiterhin stellen wir mehr Details zu diesen Techniken vor, einschließlich ihrer nützlichen Anwendungen und Grenzen.
Prompt Engineering
Prompt-Engineering ist die Kunst der Formulierung von Eingabeanfragen (Prompts, die Fragen oder Anweisungen sein können) für generative KI-Tools mit dem Ziel, die besten Ergebnisse zu erzielen. Es dient als Brücke zwischen den menschlichen Absichten und den von Maschinen erzeugten Ergebnissen. Prompt-Engineering ist vergleichbar mit dem Lehren eines Kindes durch Fragen. Eine sorgfältige Konstruktion von Input-Prompts kann dem Sprachmodell helfen, sowohl den Kontext des Inputs als auch den gewünschten Output zu verstehen. Dieser Prozess erfordert Kreativität, ein gutes Verständnis des Sprachmodells und Präzision. Die Auswahl und Anordnung der Wörter kann Ihre Ausgabe erheblich verändern.
Vorteile:
- schnell und einfach, erfordert keine Programmierkenntnisse;
- eignet sich besonders für allgemeine Aufgaben wie das Zusammenfassen von Texten, Entwürfen, Brainstorming und das Erklären von Konzepten.
Nachteile:
- Prompts werden häufig zu lang und überschreiten die Größe des Kontextfensters (Token-Grenzen).
- Kann langsam sein, wenn die Prompts lang sind.
- Der Preis steigt schnell mit langen Prompts.
- In verschiedenen Bereichen gibt es Einschränkungen, weil die allgemeinen Modelle nicht auf privaten Informationen trainiert wurden, die nicht online verfügbar sind.
- Modelle können halluzinieren, und das lässt sich nicht mit prompter Technik lösen.
- Der Schutz vor Prompt-Injektion-Angriffen kann schwierig sein.[1]
Embeddings
Embeddings stellen die semantische Bedeutung von Wörtern und Sätzen in Form eines mathematischen Vektors dar, der leicht durchsuchbar ist und mit anderen auf Ähnlichkeit verglichen werden kann. Eine der typischen Anwendungen ist die Speicherung in einer Vektorsuchdatenbank und die Integration in KI-Workflows, um Informationen für die Aufnahme in LLM-Aufforderungen abzurufen. Sie können bei der Dokumentationssuche und der Extraktion relevanter Informationen für den Kontext in LLM-Antworten helfen.
Embeddings sind gut für:
- Frage- und Antwort-Agenten, bei denen die Antworten nicht allgemein bekannt sind;
- Abrufen relevanter Informationen zur Verbesserung der Eingabeaufforderungen und der Qualität der Ausfüllungen;
- Reduzierung der Wahrscheinlichkeit von Halluzinationen, das Modell kann den bereitgestellten Kontext nutzen.
Beschränkungen:
- Das Abrufen von schlechtem Kontext wird zu einer schlechten Antwort führen. Wenn kein relevanter Kontext bereitgestellt wurde, wird LLM eine schlechte Antwort liefern.
- Die Art der Segmentierung von Informationen kann einen negativen Einfluss auf die Qualität der Antworten haben.[2]
Feinabstimmung
Feinabstimmung bedeutet, dass man ein allgemeines Sprachmodell nimmt und ihm ein spezielles Training für eine bestimmte Aufgabe gibt, z. B. die Beantwortung medizinischer Fragen oder das Schreiben von Gedichten. Dadurch wird das LLM bei dieser speziellen Aufgabe viel besser, behält aber dennoch seine allgemeinen Sprachfähigkeiten.
In der ML-Sprache wird dies auch als Transferlernen bezeichnet, bei dem die Gewichte und Verzerrungen der neuronalen Netze angepasst werden. Bei der Feinabstimmung wird das vortrainierte Modell verwendet und übernommen. Das Modell wird mit Tausenden oder Millionen von Beispielen versorgt, um zu lernen, wie es in verschiedenen Kontexten relevante Antworten erzeugen kann.
Feinabstimmung ist gut für:
- Änderung des erwarteten Formats der Prompts und Vervollständigungen.
- Bearbeitung eines hohen Anfragevolumens, da die fein abgestimmten Modelle auf spezifische Aufgaben spezialisiert sind und weniger Token in dem Prompt benötigen.
- Reduzierung des Risikos von Prompt-Injektion-Angriffen, da solche Beispiele während des Feinabstimmungsprozesses geliefert werden könnten und der LLM lernen wird, sie zu ignorieren.
Beschränkungen:
- Das Lehren eines Modells erfordert ein völlig neues Fachwissen. In diesem Fall ist es besser, Embeddings zu verwenden oder ein Basismodell auszuwählen, das bereits über dieses Fachwissen verfügt.[2]
Showcase: Entwicklung eines digitalen Marketing-Assistenten mithilfe des LangChain-Frameworks
Unser Ziel
Unser Ziel ist es, einen digitalen Marketing-Assistenten zu entwickeln, der auf einem Frage-Antwort-Systembasiert. Dieses System ist darauf zugeschnitten, Anfragen in natürlicher Sprache zu verstehen und Antworten auf dieselbe benutzerfreundliche Weise zu geben. Die Wissensgrundlage für unseren Assistenten stammt aus 33 spannenden Artikeln über digitales Marketing, die auf dem Cusaas Blog verfügbar sind: Customer Segmentation as a Service.
Um eine nahtlose Integration mit unseren Tools zu gewährleisten, haben wir jeden Artikel zunächst in ein ".txt"-Format konvertiert. Obwohl viele Tools HTML- und PDF-Formate direkt verarbeiten können, werden durch die Konvertierung in das ".txt"-Format mögliche Probleme mit der Kodierung oder dem Zeilenumbruch ausgeschlossen.
LangChain-Framework
LangChain wurde 2022 als Open-Source-Framework eingeführt, um die Entwicklung von Anwendungen mit LLM zu vereinfachen. Das Hauptziel von LangChain besteht darin, eine nahtlose Verbindung zwischen robusten LLMs und einer Vielzahl externer Datenquellen herzustellen und so die Entwicklung und Nutzung von Anwendungen zur Verarbeitung natürlicher Sprache (NLP) zu ermöglichen. Dies ermöglicht es Entwicklern, dynamische, auf Daten reagierende Anwendungen zu erstellen.
Das grundlegende Konzept hinter diesem Framework ist die Fähigkeit, verschiedene Komponenten aus unterschiedlichen Modulen zu verbinden und so komplexe Ketten zu bilden, die fortgeschrittene LLM-Anwendungsfälle bedienen können. LangChain rationalisiert die Entwicklung verschiedener Anwendungen, wie z. B. Generative Question-Answering (GQA), Chatbots und Zusammenfassungen.
Es ermöglicht Anwendungen, die sind:
- Kontextabhängig: Verbindung von LLM mit Quellen des Kontexts;
- Argumentation: sich auf ein Sprachmodell stützen, um Argumente zu finden (wie man auf der Grundlage des gegebenen Kontexts antworten kann, welche Maßnahmen zu ergreifen sind, usw.).
Die wichtigsten Bestandteile von LangChain sind Komponenten und Ketten (strukturierte Zusammenstellung von Komponenten).[3]
Im folgenden Diagramm ist der Prozess hinter der LangChain dargestellt:
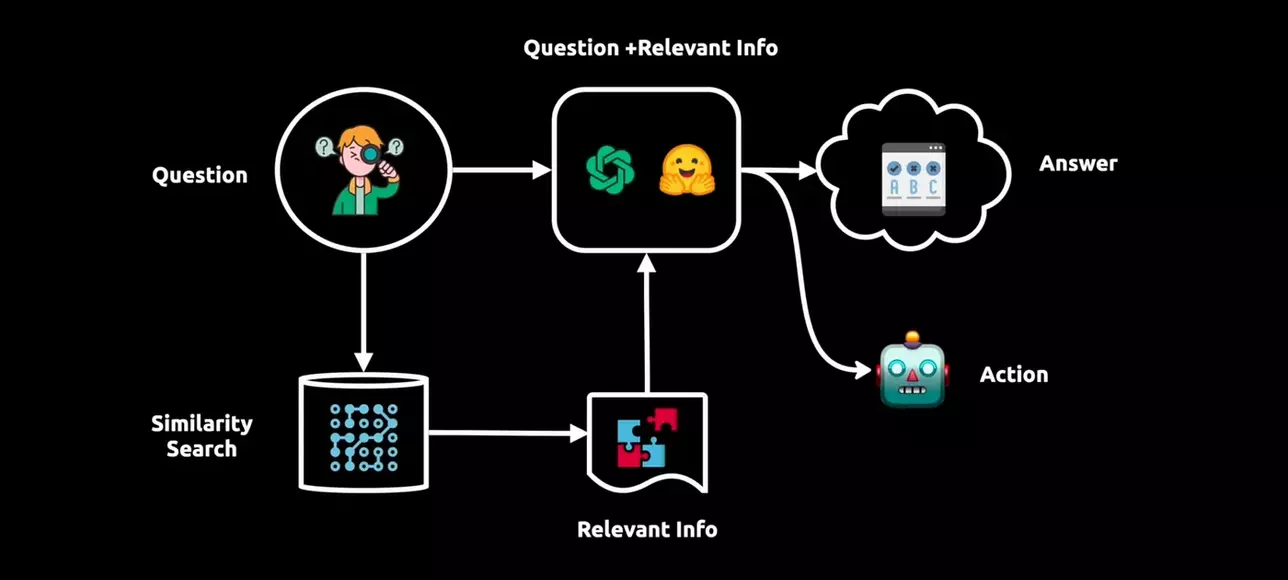
Zusammenfassung, wie LangChain und LLMs funktionieren[4]
Daher ist die Generierung von Antworten ein komplexer Prozess, der ein Sprachmodell und eine Vektordarstellung umfasst:
- Verarbeitung von Benutzeranfragen: Die Frage des Benutzers wird von dem Sprachmodell von LangChain analysiert, das auf verschiedenen Textdaten trainiert wurde, um Kontext, Syntax und Semantik zu verstehen.
- Vektorielle Darstellung: Gleichzeitig wird die Frage mithilfe der Vektorgrafentechnologie in eine Vektordarstellung umgewandelt, die die Wortbeziehungen und Bedeutungen erfasst.
- Ähnlichkeitssuche: Die Vektordarstellung der Frage des Benutzers wird für eine Ähnlichkeitssuche in der LangChain-Datenbank verwendet, wobei relevante Informationen als Vektoren untergebracht werden.
- Abrufen relevanter Informationen: Wichtige Informationen, die in engem Zusammenhang mit der Bedeutung der Frage stehen, werden mithilfe der Vektordarstellung abgerufen.
- Erweiterung der Kenntnisse des Sprachmodells: Die abgerufenen Informationen bereichern das Kontextverständnis des Sprachmodells, indem sie die ursprüngliche Anfrage mit Erkenntnissen aus der Datenbank kombinieren.
- Antwortgenerierung oder Aktion: Auf der Grundlage dieses umfassenden Wissens liefert das Sprachmodell eine präzise Antwort oder ergreift relevante Maßnahmen, um kontextbezogene Ergebnisse zu erreichen.[5]
Tests
Die Tests wurden mit der folgenden Hardware-Konfiguration durchgeführt: 11th Gen Intel® Core™ i7-11370H @ 3.30GHz, 16 GB RAM, und NVIDIA GeForce MX450 mit 2GB GDDR5.
Die folgenden Schritte wurden durchgeführt:
- Installierte Python und die erforderlichen Bibliotheken, einschließlich LangChain.
- Herunterladen der gewünschten LLM-Modelle von HuggingFace zum Testen.
- Ausgewählt wurden 33 Artikel aus dem Cusaas Blog im HTML-Format.
- Python Script wurde entwickelt, das LangChain und andere wichtige Bibliotheken verwendet.
- Die Artikel wurden in das LLM-Modell aufgenommen (hochgeladen).
- Python Scripts wurden ausgeführt und die Antworten auf der Grundlage der Artikel abgerufen.
Die folgenden Modelle wurden bewertet:
-
GGML-Modelle:
- llama-2-7b-chat.ggmlv3.q2_K.bin
- llama-2-13b-chat.ggmlv3.q2_K.bin
- vicuna-13b-v1.5-16k.ggmlv3.q2_K.bin
- llama-2-13b.ggmlv3.q2_K.bin
-
LLama.CPP(GGUF)-Modelle:
- llama-2-7b-chat.Q5_K_M.gguf
- llama-2-13b-chat.Q5_K_M.gguf
- llama-2-13b-chat.Q6_K.gguf
Die besten Antworten wurden mit dem Modell "llama-2-13b-chat.Q6_K.gguf" erhalten.
Fazit
Für diejenigen, die ein Höchstmaß an Flexibilität oder die Integration in eine andere Plattform anstreben, ist das LangChain-Framework eine erstklassige Wahl auf dem aktuellen Markt. Allerdings bringt dieser Ansatz eine Reihe von Herausforderungen mit sich, wie die Notwendigkeit, Code zu schreiben und Stabilität und Sicherheit zu gewährleisten.
Hier ist ein kurzer Überblick:
Vorteile:
- Bietet unvergleichliche Flexibilität für individuelle Projekte, da es sich um ein Framework handelt, das programmatisch in verschiedene Lösungen mit Python oder JavaScript integriert werden kann.
- Erleichtert die reibungslose Integration mit bekannten KI-Plattformen wie OpenAI und Hugging Face und vereinfacht den Prozess zur Nutzung modernster LLMs.
- Bietet eine umfassende Dokumentation.
- Entwickelt sich zu einem führenden Framework für LLMs mit aktiver Weiterentwicklung.
- Die Dokumentenaufnahme ist effizient und schnell.
- Unterstützt ein breites Spektrum von Dokumenttypen für die Aufnahme.
- Liefert hochpräzise Antworten, wenn ein geeignetes Modell gewählt wird.
- Garantiert erstklassigen Datenschutz, da es vor Ort betrieben werden kann, ohne dass eine Internetverbindung erforderlich ist.
- Hat das Potenzial, bei Bedarf in der Cloud zu laufen.
- LangChain ist Open-Source und völlig kostenlos.
- Bietet Flexibilität bei der Wahl des Modells, von Open-Source bis zu kommerziellen Angeboten, einschließlich derer von OpenAI.
- Mit GPU-Beschleunigung, insbesondere bei Verwendung von LLama.CPP-kompatiblen GGUF-Modellen, kann die Antwortgenerierung schnell erfolgen.
Nachteile:
- Erfordert gute Kenntnisse in der Softwareentwicklung.
- Die Lösung ist möglicherweise nicht immer stabil; es hat Fälle gegeben, in denen der Python-Kernel abgestürzt ist, möglicherweise aufgrund von Hardwarebeschränkungen. Weitere Tests mit erweitertem
- Arbeitsspeicher sind erforderlich.
- Da es sich um eine relativ neue Bibliothek handelt, könnte sie bestimmte unentdeckte Fehler oder Probleme aufweisen.
- Aufgrund ihres Open-Source-Charakters, fehlt es an externer Unterstützung.
- Die Navigation in den Funktionen und die Maximierung des Potenzials könnten eine Lernkurve erfordern.
Weitere Ansätze zum Aufbau eines digitalen Marketingassistenten
Im Folgenden finden Sie einen kurzen Überblick über alternative Ansätze zur Entwicklung von KI-Assistenten für Unternehmen.
Cloud
-
OpenAI API
OpenAI API ist eine Cloud-Schnittstelle, die auf Microsoft Azure gehostet wird. Sie ermöglicht den Nutzern den Zugriff auf neue, von OpenAI entwickelte, vortrainierte KI-Modelle, wie GPT-3.5 Turbo, GPT-4, DALL-E und Codex. Im Gegensatz zu den meisten KI-Systemen, die in der Regel für einen bestimmten Anwendungsfall konzipiert sind, bietet die OpenAI-API Entwicklern eine universell einsetzbare Cloud-Plattform für Texteingabe und -ausgabe.[6] -
Microsoft Azure OpenAI + Azure Cognitive Search
Azure Cognitive Search ist ein Cloud-basierter Suchdienst, der es Entwicklern ermöglicht, KI-gestützte Sucherfahrungen und generative KI-Apps zu erstellen, die große Sprachmodelle mit Unternehmensdaten kombinieren. Azure OpenAI Service ist ein Dienst, der Zugriff auf die fortschrittlichsten KI-Sprachmodelle wie GPT-3.5 Turbo und GPT-4 bietet. In Kombination mit Azure Cognitive Search können Entwickler diese Modelle auf ihre Suchlösungen anwenden und dabei ihre eigenen Daten als Grundlage für die Antworten verwenden. Dieser Ansatz wird in unserem nächsten Blog detaillierter beschrieben -
Amazon Kendra
Es handelt sich um einen intelligenten Suchdienst, der natürliche Sprachverarbeitung und fortschrittliche ML-Algorithmen verwendet, um spezifische Antworten auf Suchfragen aus Ihren eigenen Daten zu liefern. Im Gegensatz zur herkömmlichen schlagwortbasierten Suche nutzt Amazon Kendra seine semantischen und kontextbezogenen Verständnisfähigkeiten, um zu entscheiden, ob ein Dokument für eine Suchanfrage relevant ist. Es ist möglich, mehrere Daten-Repositorien mit einem Index zu verbinden und Dokumente aufzunehmen und zu crawlen. Man kann seine eigenen Dokument-Metadaten verwenden, um eine funktionsreiche und maßgeschneiderte Suche zu erstellen.[7] -
IBM Watson Discovery + Assistant
IBM Watson Discovery ist ein Dienst, der sich auf die proaktive Suche nach verborgenen Erkenntnissen durch Content Mining konzentriert und den Nutzern hilft, mithilfe einer geführten Navigation schnell an Informationen zu gelangen. IBM Watson Assistant ermöglicht die Entwicklung von Chatbots für die Bereitstellung von Informationen aus analysierten Quellinhalten. Mit einer Kombination aus Watson Assistant und Watson Discovery können Unternehmen Chatbots erstellen, die wertvolle Erkenntnisse aus den analysierten Inhalten liefern. -
Microsoft Azure Cognitive Search + AI Bot Service
Microsoft Azure Cognitive Search ist ein cloudbasierter Suchdienst, der die Indizierung und Suche in verschiedenen Datenquellen ermöglicht. Azure Bot Service ist ein Teil von Microsofts Bot Framework, mit dem Entwickler intelligente Chatbots und virtuelle Assistenten erstellen können. Diese Chatbots können mit Azure Cognitive Search integriert werden, um Q&A-Systeme zu erstellen. -
Elastic Enterprise Search
Elastic Enterprise Search ist eine leistungsstarke Suchplattform von Elastic, die die Erstellung einer einheitlichen Suche über verschiedene Datenquellen und Inhaltstypen hinweg ermöglicht. Durch die Verknüpfung von Benutzeranfragen mit dem indizierten Inhalt ermöglicht sie es Q&A-Systemen, effizient relevante Antworten abzurufen und bereitzustellen und so die Genauigkeit und Geschwindigkeit der Antworten auf Benutzerfragen zu verbessern. Darüber hinaus bietet sie Funktionen für die Relevanzabstimmung und die Anpassung, wodurch die allgemeine Benutzererfahrung in Q&A-Anwendungen verbessert wird.
On-Premises
-
PrivateGPT (Open-Source-Version)
PrivateGPT ist ein Open-Source-Projekt auf GitHub, das sich der Erstellung einer vertraulichen Variante des GPT-Sprachmodells zum Ziel gesetzt hat. Die Initiative hinter diesem Projekt ist die Erforschung der Machbarkeit eines vollständig privaten Ansatzes zur Beantwortung von Fragen mit LLMs und Vektoreinbettungen. Mit PrivateGPT können Abfragen an Dokumente ohne Internetverbindung gestellt werden, wobei die Stärken von LLMs genutzt werden. Dies garantiert 100% Privatsphäre, da die Daten auf die Ausführungsumgebung beschränkt bleiben. PrivateGPT stützt sich auf mehrere Technologien, darunter LangChain, GPT4All, LlamaCpp, Chroma und SentenceTransformers, die wir in unserem nächsten Blog detaillierter beschreiben werden. -
Private AI (Kommerzielles PrivatGPT)
Es ist eine kommerzielle Version von PrivateGPT. Die PrivateGPT-Chat-Benutzeroberfläche besteht aus einer Weboberfläche und dem Container von Private AI. Es nutzt den Microsoft Azure OpenAI Service statt OpenAI direkt, da der Azure Service bessere Datenschutz- und Sicherheitsstandards bietet. Der Vorteil ist, dass die neuesten und leistungsfähigsten Modelle wie GPT-3.5 Turbo, GPT-4 verwendet werden können.[8] -
h2oGPT
h2oGPT ist eine quelloffene GitHub-Suite von Code-Repositories, die die Erstellung und Verwendung von LLMs auf der Grundlage von Generative Pretrained Transformers (GPTs) ermöglichen. Sie bietet ein umfassendes Framework, das ein LLM-Feinabstimmungssystem, eine benutzerfreundliche Chatbot-Schnittstelle und Frage-Antwort-Funktionen für Dokumente umfasst. -
Oobabooga
Oobabooga ist eine quelloffene GitHub-Web-UI zur Texterstellung für die Interaktion mit Open-Source-Modellen. Es bietet Funktionen für die Erzeugung von Texten, kreatives Schreiben und die Übersetzung von Formen von Sprachen mit hohem Inhalt. Oobabooga unterstützt mehrere Modell-Backends wie die Transformatoren llama.cpp, ExLlama, ExLlamaV2, AutoGPTQ, GPTQ-for-LLaMA und CTransformers. Es ermöglicht einen schnellen Wechsel zwischen den verschiedenen Modellen im laufenden Betrieb. Alle Modelle von HuggingFace werden unterstützt. -
GPT4all Chat Client und GTP4all API for Python
GPT4All ist ein Open-Source-Ökosystem von GitHub zum Trainieren und Bereitstellen leistungsstarker und angepasster LLMs, die lokal auf Consumer-Grade-CPUs/GPUs laufen.
Der GPT4all Chat Client ist eine kostenlose Desktop-Anwendung, mit der Sie jede lokale LLM ausführen können. Er unterstützt Modelle aller neueren Versionen von GGML und llama.cpp.
Der Desktop-Client wird nicht für die Produktion empfohlen, da er relativ neu ist und noch nicht stabil funktioniert. Die GPT4All-API (derzeit in der Anfangsphase der Entwicklung) stellt REST-API-Endpunkte zum Sammeln von Vervollständigungen und Einbettungen von großen Sprachmodellen zur Verfügung.[9] -
LM Studio
LM Studio ist ein unabhängiges Projekt, das darauf abzielt, die lokale Ausführung von LLMs zugänglicher und kostengünstiger zu machen. Es hat eine benutzerfreundliche Schnittstelle, die es Ihnen ermöglicht, LLMs lokal offline auszuführen. Es bietet eine einfache Möglichkeit, LLMs über die In-App-Chat-Benutzeroberfläche oder einen OpenAI-kompatiblen lokalen Server ohne komplexe Einrichtungsanforderungen zu verwenden. Alle Open-Source-Modelle von HuggingFace werden unterstützt.[10] -
LLama.CPP
llama.cpp ist eine Open-Source Portierung des LLaMA-Modells in C/C++ auf GitHub. Es ist eine Laufzeitumgebung für LLaMA-Modelle, die in C geschrieben wurden. Sie ermöglicht die lokale Ausführung von LLaMA-Modellen und bietet Unterstützung für Linux-, Windows- und Mac-Plattformen.
"Enterprise AI in Action" Whitepaper
Danke! Hier ist Ihr Download-Link:
Verweise
-
[1] Approaches
to AI: When to Use Prompt Engineering, Embeddings, or Fine-tuning
What is Prompt Engineering? A Detailed Guide
What Is Prompt Engineering? Definition and Examples - [2] Approaches to AI: When to Use Prompt Engineering, Embeddings, or Fine-tuning
-
[3] Introduction
| Langchain
Overview of LangChain
What Is LangChain andHow to Use It: A Guide
What is LangChain? A Beginners Guide With Examples - [4] Building a video assistant leveraging Large Language Models
- [5] What is LangChain? - Everything You Need to Know | Intellipaat
- [6] What is an OpenAI API, and how to use it? | .addepto
- [7] What is Amazon Kendra? | AWS
- [8] What is PrivateGPT?
-
[9] nomic-ai /
gpt4all | GitHub
GPT4All Documentation - [10] Discover, download, and run local LLMs | LM Studio



