Generative AI: Advanced Customization Techniques
Welcome to our blog. Today, we will show you LLM customization techniques that allow you to use your own data as a knowledge base. We'll cover essential topics such as Prompt Engineering, Embeddings, and Fine-tuning. Additionally, you will see a practical example of creating a Digital Marketing Assistant using the LangChain Framework. You will also learn about alternative approaches to building such assistants, whether in the cloud or on-premises.
- Introduction
-
Customization Techniques
-
Showcase: Building a Digital Marketing Assistant using
LangChain Framework
-
Other approaches to building digital marketing
assistant
- References
Introduction
In the enterprise context, implementation of various use cases requires nuanced customization approaches. Most enterprises possess unique datasets, untouched by standard AI models. Therefore, to build robust AI assistants tailored to such enterprise-specific information, merely relying on pre-trained models isn't sufficient. Instead, specialised techniques come into play, ensuring the AI comprehends and engages meaningfully with the distinctiveness of the data. In this article, we'll check some of the advanced customization techniques that make this possible.
Customization Techniques
Therefore, when addressing domain-specific inquiries rooted in unique enterprise data, standard AI models may not suffice due to their unfamiliarity with such specialised content. In these situations, advanced customization techniques of generative AI become imperative:
- Prompt engineering facilitates the construction of input queries tailored to specific data and inquiries, ensuring that the model discerns the underlying intent.
- Embeddings are instrumental in encoding semantics, aiding the LLM in capturing the context and subtleties of domain-specific language.
- Fine-tuning refines the LLM to be attuned to enterprise data, optimising its performance and ensuring congruence with the particular industry or domain. Absent this refinement, the model might fall short in delivering accurate or pertinent responses regarding enterprise data, due to a deficit in contextual awareness and specialised comprehension of an organisation's proprietary information.
All these techniques empower LLMs to become highly effective tools for processing and extracting insights from your proprietary data. Such advanced techniques are especially crucial, when:
- Precision matters: If you need precise and controlled responses from an LLM, prompt engineering allows you to guide its output effectively.
- Semantic understanding is important: When your application requires a deep understanding of word meanings and context, embeddings can help by representing language in a mathematical vectorized form.
- Specialised tasks: For tasks that demand domain-specific or context-specific expertise, fine-tuning allows you to tailor the LLM to excel in those areas.
- Enhanced performance: When you aim to significantly enhance the LLM's performance on a particular task or domain, these techniques can yield more accurate and context-aware results.
- Resource optimization: Depending on your available resources, these techniques can be used individually or in combination to optimise the model's capabilities efficiently.
Further, we introduce more details on these techniques, including their beneficial applications and limitations.
Prompt Engineering
Prompt engineering is the art of formulating input queries (prompts, which can be questions or instructions) for generative AI tools with the goal of achieving the best results. It serves as a bridge connecting human intention with the outcomes generated by machines. Prompt engineering is similar to teaching a child through questions. Careful construction of input prompts can help the language model in understanding both the context of the input and your desired output. This process requires creativity, a good understanding of the language model, and precision. The selection and arrangement of words can significantly change your output.
Benefits:
- quick and easy, doesn’t require coding skills;
- great at general tasks like summarising text, drafts, brainstorming ideas, and explaining concepts.
Limitations:
- Prompts tend to get long and exceed context window size (token limits).
- Can be slow if prompts are long.
- Price is increasing fast with long prompts.
- Limitations in various domains exist because generic models weren’t trained on private information that’s not available online.
- Model can hallucinate, and this can’t be solved with prompt engineering.
- Protection from prompt injection attacks can be difficult.[1]
Embeddings
Embeddings represent semantic meaning of words and phrases in a mathematical vector form, which can be easily searched and compared to each other for similarity. One of the typical uses for them is storing in a vector search database and integrating them into AI workflows to retrieve information for inclusion in LLM prompts. They can help in documentation search and extracting relevant information for context in LLM responses.
Embeddings are good for:
- question and answer agents where the answers are not common public knowledge;
- retrieving of relevant information to improve your prompts and quality of completions;
- reducing hallucination probability, the model can use the provided context.
Limitations:
- Retrieving bad context will result in a bad answer. If relevant context wasn’t provided, LLM will provide a poor response.
- Way of information segmentation can have an impact on the answers quality.[2]
Fine-tuning
Fine-tuning means taking a general-purpose language model and giving it specialised training for a particular job, like answering medical questions or writing poetry. This makes the LLM much better at that specific task while still retaining its general language skills.
In ML-Language it is also called transfer learning during which weights and biases of neural networks are adjusted. Fine-tuning uses the pre-trained model and adopts it. The model is provided with thousands or millions of examples to learn how to generate relevant responses in various contexts.
Fine-tuning is good for:
- Changing the expected format of your prompt and completions.
- Processing a high volume of requests, because the fine-tuned models are specialised for specific tasks and require fewer tokens in the prompt.
- Reducing the risk of prompt injection attacks, because such examples could be provided during the fine-tuning process and the LLM will learn to ignore them.
Limitations:
- Teaching a model, a completely new domain knowledge. In this case, it is better to use embeddings or select a base model that already has this domain knowledge.[2]
Showcase: Building a Digital Marketing Assistant using LangChain Framework
Our goal
Our goal is to build a Digital Marketing Assistant powered by a Question Answering System. This system is tailored to understand queries in natural language and provide answers in the same user-friendly manner. The knowledge foundation for our assistant is derived from 33 insightful articles on digital marketing available on the Cusaas Blog: Customer Segmentation as a Service.
To ensure a seamless integration with our tools, we've initiated the process by converting each article into a ".txt" format. While many tools can directly handle HTML and PDF formats, converting to ".txt" sidesteps potential issues with encoding or line breaks.
LangChain framework
LangChain was introduced in 2022 as an open-source framework created to simplify the development of applications using LLM. LangChain's primary objective is to establish a seamless connection between robust LLMs and a diverse range of external data sources, thus enabling the development and utilisation of natural language processing (NLP) applications. This allows developers to build dynamic, data-responsive applications.
The fundamental concept behind this framework is the ability to connect different components from various modules, forming complex chains that can serve advanced LLM use cases. LangChain streamlines the development of different applications, such as Generative Question-Answering (GQA), chatbots and summarization.
It enables applications that are:
- Context-aware: connect LLM to sources of context;
- Reasoning: rely on a language model to reason (about how to answer based on provided context, what actions to take, etc.).
The main value propositions of LangChain are components and chains (structured assembly of components).[3]
In the following schema is shown the process behind the LangChain:
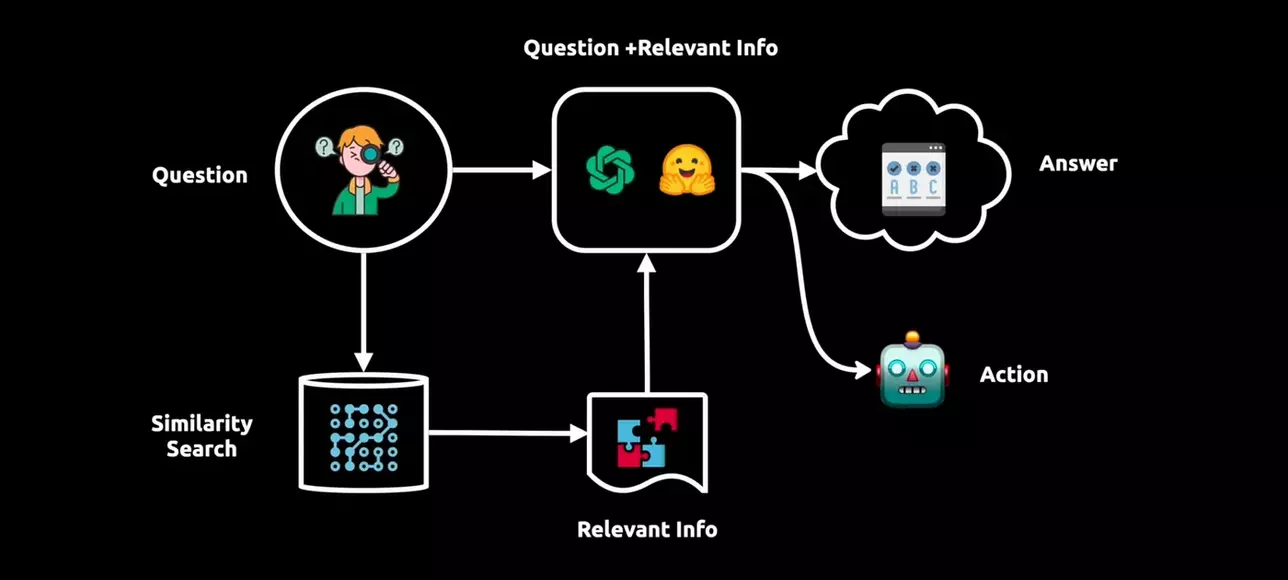
Summary how LangChain and LLMs work[4]
Thus, response generation is a complex process, involving a language model and vector representation:
- User Query Processing: The user's question is analysed by LangChain's language model, trained on diverse text data, to understand context, syntax, and semantics.
- Vector Representation: Simultaneously, the question is transformed into a vector representation using vector graph technology, capturing word relationships and meanings.
- Similarity Search: Vector representation of the user's question is used for a similarity search in LangChain's database, housing relevant information as vectors.
- Fetching Relevant Information: Important information closely connected to the question's meaning is retrieved using the vector representation.
- Enhancing Language Model's Knowledge: The retrieved information enriches the language model's context understanding, combining the original query with database insights.
- Answer Generation or Action: Using this comprehensive knowledge, the language model provides an accurate response or takes relevant actions, ensuring contextually informed results.[5]
Tests
The tests were conducted using the following hardware configuration: 11th Gen Intel® Core™ i7-11370H @ 3.30GHz, 16 GB RAM, and NVIDIA GeForce MX450 with 2GB GDDR5.
The subsequent steps were executed:
- Installed Python and requisite libraries, including LangChain.
- Downloaded the desired LLM models from HuggingFace for testing.
- Selected 33 articles from the Cusaas Blog in HTML format.
- Developed a Python script utilising LangChain and other essential libraries.
- Ingested (uploaded) the articles into the LLM model.
- Ran the Python script and retrieved answers based on the articles.
The next models were evaluated:
-
GGML models:
- llama-2-7b-chat.ggmlv3.q2_K.bin
- llama-2-13b-chat.ggmlv3.q2_K.bin
- vicuna-13b-v1.5-16k.ggmlv3.q2_K.bin
- llama-2-13b.ggmlv3.q2_K.bin
-
LLama.CPP (GGUF) models:
- llama-2-7b-chat.Q5_K_M.gguf
- llama-2-13b-chat.Q5_K_M.gguf
- llama-2-13b-chat.Q6_K.gguf
The best answers were received with the help of “llama-2-13b-chat.Q6_K.gguf” model.
Conclusion
For those seeking utmost flexibility or integration into another platform, the LangChain Framework stands out as a premier choice available in the current market. However, adopting this approach comes with its own set of challenges, such as the necessity to write code and ensure stability and security.
Here's a brief overview:
Pros:
- Provides unparalleled flexibility for individual projects as it's a framework that can be programmatically integrated into various solutions using Python or JavaScript.
- Facilitates smooth integration with renowned AI platforms like OpenAI and Hugging Face, streamlining the process to leverage cutting-edge LLMs.
- Offers comprehensive documentation.
- Emerges as a leading framework for LLMs with active ongoing development.
- Document ingestion is streamlined and rapid.
- Supports a broad spectrum of document types for ingestion.
- Delivers highly accurate answers when an appropriate model is chosen.
- Guarantees top-tier privacy since it can operate on-premise without necessitating internet connectivity.
- Has the potential to run in the cloud, if needed.
- LangChain is open-source and entirely free of charge.
- Offers flexibility in model choice, from open-source to commercial offerings, including those from OpenAI.
- With GPU acceleration, especially using LLama.CPP-compatible GGUF models, response generation can be swift.
Cons:
- Demands proficiency in software development.
- The solution might not always be stable; there have been instances where the Python kernel has crashed, potentially due to hardware constraints. Further testing with enhanced RAM might be necessary.
- Being a relatively recent library, it might have certain undetected bugs or issues.
- Lacks external support given its open-source nature.
- Navigating its functionalities and maximising its potential might require a learning curve.
Other approaches to building digital marketing assistant
Here is a brief overview of alternative approaches to building enterprise AI-assistants.
Cloud
-
OpenAI API
OpenAI API is a cloud interface hosted on Microsoft Azure. It gives users access to new pre-trained AI models developed by OpenAI, such as GPT-3.5 Turbo, GPT-4, DALL-E and Codex. Unlike most AI systems, which are usually designed for one use case, the OpenAI API provides developers with a general-purpose text-in and text-out cloud platform.[6] -
Microsoft Azure OpenAI + Azure Cognitive Search
Azure Cognitive Search is a cloud-based search service that allows developers to build AI-powered search experiences and generative AI apps that combine large language models with enterprise data. Azure OpenAI Service is a service that provides access to the most advanced AI language models such as GPT-3.5 Turbo and GPT-4. When combined with Azure Cognitive Search, it allows developers to apply these models to their search solutions using their own data as the basis for responses. This approach will be described more detailed in our next blog. -
Amazon Kendra
It is an intelligent search service that uses natural language processing and advanced ML algorithms to return specific answers to search questions from your own data. Unlike traditional keyword-based search, Amazon Kendra uses its semantic and contextual understanding capabilities to decide whether a document is relevant to a search query. It is possible to connect multiple data repositories to an index and ingesting and crawling documents. One can use its own document metadata to create a feature-rich and customised search.[7] -
IBM Watson Discovery + Assistant
IBM Watson Discovery is a service that focuses on proactively finding hidden insights through content mining and helps users quickly surface information by using a guided navigation experience. IBM Watson Assistant allows the development of chatbots for information delivery from analysed source content. With a combination of Watson Assistant and Watson Discovery, businesses can create chatbots that provide valuable insights from the analysed content. -
Microsoft Azure Cognitive Search + AI Bot Service
Microsoft Azure Cognitive Search is a cloud-based search service that allows indexing and searching through various data sources. Azure Bot Service is a part of Microsoft's Bot Framework, allowing developers to create intelligent chatbots and virtual assistants. These chatbots can be integrated with Azure Cognitive Search to build Q&A systems. -
Elastic Enterprise Search
Elastic Enterprise Search is a powerful search platform offered by Elastic that allows the creation of unified search across various data sources and content types. By connecting user queries to the indexed content, it enables Q&A systems to efficiently retrieve and provide relevant answers, improving the accuracy and speed of responses to user questions. Additionally, it offers features for relevance tuning and customization, enhancing the overall user experience in Q&A applications.
On-Premises
-
PrivateGPT (open-source version)
PrivateGPT is an open source GitHub project dedicated to creating a confidential variant of the GPT language model. The initiative behind this project is to explore the feasibility of a completely private approach to question answering using LLMs and Vector embeddings. With PrivateGPT, queries can be posed to documents without an internet connection, leveraging the strengths of LLMs. This guarantees 100% privacy, as data remains confined within the execution environment. PrivateGPT draws from multiple technologies including LangChain, GPT4All, LlamaCpp, Chroma, and SentenceTransformers.
This approach will be described more detailed in our next blog. -
Private AI (Commercial PrivateGPT)
It is a commercial version of PrivateGPT. The PrivateGPT chat UI consists of a web interface and Private AI's container. It uses the Microsoft Azure OpenAI Service instead of OpenAI directly, because the Azure service offers better privacy and security standards. Advantage is that the latest most powerful models such as GPT-3.5 Turbo, GPT-4 could be used.[8] -
h2oGPT
h2oGPT is an open-source GitHub suite of code repositories that allow the creation and use of LLMs based on Generative Pretrained Transformers (GPTs). It provides a comprehensive framework that includes a LLM fine-tuning system, a user-friendly chatbot interface, and document question-answer capabilities. -
Oobabooga
Oobabooga is an open-source GitHub text-generation web UI for interacting with open-source models. It provides features for generating texts, creative writing, and translating forms of languages with high content. Oobabooga supports multiple model backends such as transformers llama.cpp, ExLlama, ExLlamaV2, AutoGPTQ, GPTQ-for-LLaMA, and CTransformers. It allows quickly switch between different models on the fly. All models from HuggingFace are supported. -
GPT4all Chat Client and GTP4all API for Python
GPT4All is an open-source ecosystem from GitHub to train and deploy powerful and customised LLMs that run locally on consumer grade CPUs/GPUs.
GPT4all Chat Client is a free desktop application that allows you to run any local LLM. It supports models from all newer versions of GGML and llama.cpp.
Desktop client is not recommended for production, because it is relatively new and works not stable yet. The GPT4All API (right now is under initial development) exposes REST API endpoints for gathering completions and embeddings from large language models.[9] -
LM Studio
LM Studio is an independent project that aims to make running LLMs locally more accessible and cost-effective. It has a user-friendly interface that allows you to run LLMs locally offline. It provides an easy way to use LLMs through the in-app Chat UI or an OpenAI compatible local server without complex setup requirements. All open-source models from HuggingFace are supported.[10] -
LLama.CPP
llama.cpp is an open-source GitHub port of LLaMA model in C/C++. It is a runtime for LLaMA models written in C. It allows you to execute LLaMA models locally and provides support for Linux, Windows, and Mac platforms.
"Enterprise AI in Action" Whitepaper
Thanks! Here is your download-link:
References
-
[1] Approaches
to AI: When to Use Prompt Engineering, Embeddings, or Fine-tuning
What is Prompt Engineering? A Detailed Guide
What Is Prompt Engineering? Definition and Examples - [2] Approaches to AI: When to Use Prompt Engineering, Embeddings, or Fine-tuning
-
[3] Introduction
| Langchain
Overview of LangChain
What Is LangChain andHow to Use It: A Guide
What is LangChain? A Beginners Guide With Examples - [4] Building a video assistant leveraging Large Language Models
- [5] What is LangChain? - Everything You Need to Know | Intellipaat
- [6] What is an OpenAI API, and how to use it? | .addepto
- [7] What is Amazon Kendra? | AWS
- [8] What is PrivateGPT?
-
[9] nomic-ai /
gpt4all | GitHub
GPT4All Documentation - [10] Discover, download, and run local LLMs | LM Studio



